
- Pro
In an exclusive interview, the company reveals its bold vision for scalable, practical real world AI
When you purchase through links on our site, we may earn an affiliate commission. Here’s how it works.
 (Image credit: Multiverse Computing)
(Image credit: Multiverse Computing)
- Copy link
- X
- Threads
Sign up for breaking news, reviews, opinion, top tech deals, and more.
Contact me with news and offers from other Future brands Receive email from us on behalf of our trusted partners or sponsors By submitting your information you agree to the Terms & Conditions and Privacy Policy and are aged 16 or over.You are now subscribed
Your newsletter sign-up was successful
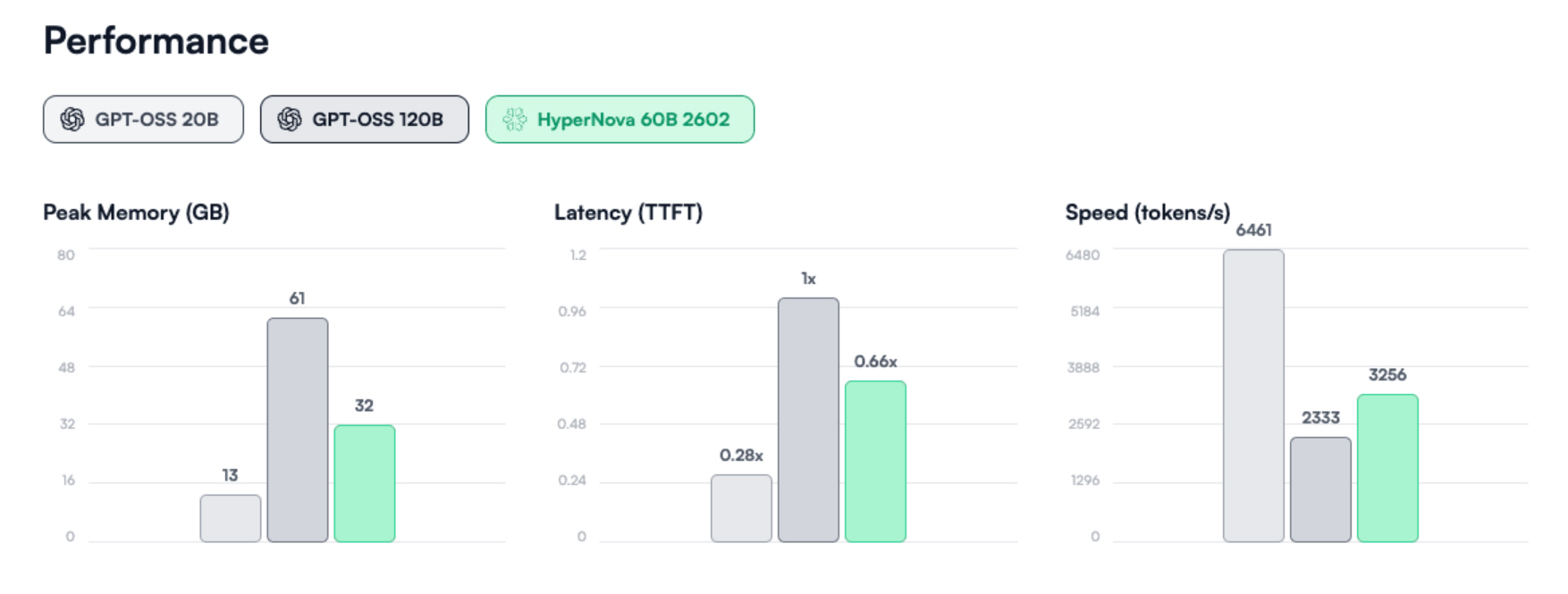
An account already exists for this email address, please log in. Subscribe to our newsletterSpanish AI company Multiverse Computing has released HyperNova 60B 2602, a compressed version of OpenAI’s gpt-oss-120B, and published it for free on Hugging Face.
The new version cuts the original model’s memory needs from 61GB to 32GB, and Multiverse says it retains near-parity tool-calling performance despite the 50% reduction in size.
In theory, this means a model that once required heavy infrastructure can run on far less hardware. For developers with tighter budgets or energy constraints, that’s a potentially huge advantage.
You may like-
 World's smallest AI supercomputer achieves world record with 120B-parameter LLM support on-device — what I don't understand, though, is how it does OTA hardware upgrades
World's smallest AI supercomputer achieves world record with 120B-parameter LLM support on-device — what I don't understand, though, is how it does OTA hardware upgrades
-
 Sam Altman says ChatGPT water use claims are ‘completely untrue'
Sam Altman says ChatGPT water use claims are ‘completely untrue'
-
 Deepseek may have found a way to solve the RAM crisis by eliminating the need for expensive HBM for AI inference and training — yes, the very reason why DRAM prices went up by 5X in 10 weeks
Deepseek may have found a way to solve the RAM crisis by eliminating the need for expensive HBM for AI inference and training — yes, the very reason why DRAM prices went up by 5X in 10 weeks
CompactifAI technology
Multiverse claims gains in agent-focused benchmarks compared to its earlier compressed release. It says HyperNova 60B 2602 delivers a 5x improvement on Tau2-Bench and 2x on Terminal Bench Hard.
Those tests measure tool use and coding workflows rather than simple text replies.
The company’s CompactifAI technology restructures transformer weight matrices using quantum-inspired tensor networks.
Multiverse believes that effective compression offers an alternative to simply building larger and larger models, and links that view to ongoing European discussions around sovereign AI, infrastructure limits, and energy use - so to find out more, I spoke to the company about its compression technology.
Are you a pro? Subscribe to our newsletterContact me with news and offers from other Future brandsReceive email from us on behalf of our trusted partners or sponsorsBy submitting your information you agree to the Terms & Conditions and Privacy Policy and are aged 16 or over.- How can you compress an LLM?
Multiverse Computing compresses large language models using its proprietary CompactifAI technology, based on quantum-inspired tensor networks.
Instead of simply removing parameters, CompactifAI restructures the internal weight matrices of transformer models into highly efficient tensor network representations. This mathematical reformulation captures correlations between parameters and eliminates structural redundancy.
The process is applied post-training, meaning the original model does not need to be retrained and no access to the original training data is required.
You may like-
World's smallest AI supercomputer achieves world record with 120B-parameter LLM support on-device — what I don't understand, though, is how it does OTA hardware upgrades
-
Sam Altman says ChatGPT water use claims are ‘completely untrue'
-
Deepseek may have found a way to solve the RAM crisis by eliminating the need for expensive HBM for AI inference and training — yes, the very reason why DRAM prices went up by 5X in 10 weeks
Using this approach, CompactifAI can reduce memory usage by up to approximately 93% and significantly cut parameter counts, while maintaining strong performance across tasks.
The resulting compressed models are smaller, faster, more energy-efficient, and easier to deploy across cloud, on-premise, and edge environments.
- Can you apply it to every LLM?
It works on transformer-based large language models, including dense foundation models, provided access to the model weights is available.
The technology is architecture-agnostic within the transformer family and does not require changes to the model’s external behavior or APIs.
Compression effectiveness depends on the level of redundancy in the model. Large, overparameterized models typically offer the greatest compression potential.
- What are the challenges?
The primary technical challenge is preserving model accuracy while achieving high compression ratios. This is addressed by carefully controlling tensor decomposition parameters to balance size reduction and performance stability.
Another challenge is ensuring that compressed models maintain robustness across different tasks, including reasoning, multilingual performance, and domain-specific use cases.
Finally, deployment environments vary widely. Compression must be optimized for different hardware targets, latency requirements, and operational constraints.
- What could a good analogy be?
Rewriting the blueprint, not removing bricks: CompactifAI does not simply remove parts of a model. Instead, it rewrites the mathematical blueprint so the same structure is represented more efficiently.
It is like redesigning a building’s internal framework so it uses far less material while preserving strength and functionality.
Another analogy is reorganizing a massive archive into a highly structured system that eliminates duplication. The knowledge remains intact, but it is encoded far more efficiently.
- How do you determine accuracy loss?
Accuracy loss is determined by benchmarking the compressed model against the original on the same tasks and scoring metrics, then measuring the change.
In practice, that includes tool-calling evaluations. Reducing a loss in capability here enables more advanced agentic workflows and coding applications.
- What other companies (perhaps rivals) are working on the same technique
Multiverse Computing’s compression technique is totally unique, based on research into quantum-inspired tensor networks by cofounder and CEO Roman Orus.
Though there are other techniques available for compressing AI models, they come with the trade-off of a much higher degree of accuracy loss.
- Given the fact that LLMs organically evolve over time, what could be the future of your compression (hardware implementation maybe?) or something else?
This compression technique can be applied to upcoming LLMs as well, meaning that in the future, devices such as cars, phones, laptops etc. will be able to run small or nano AI models preinstalled on their hardware.
- Is it hardware agnostic? Does it work better with some hardware (ASIC) than others?
Yes, it’s hardware-agnostic at the model level: CompactifAI compresses the model weights post-training, so the resulting model can be deployed across cloud, on-prem, and edge without changing the model’s external interface.
Inference speedups depend on what was limiting you before: If you were memory-bound, a smaller model often runs significantly faster and cheaper on the same hardware.
It doesn’t require an ASIC, but GPUs/AI accelerators will typically deliver the highest throughput for transformer inference once the model fits comfortably in memory.
- What does the compression rely on?
CompactifAI relies on redundancy in trained transformer weight matrices: large models are often overparameterised, so the same behaviors can be represented with fewer effective parameters.
Instead of generic “zip-style” compression, it uses a model-aware factorization (quantum-inspired tensor networks) to rewrite large matrices into a structured, smaller form while mitigating the accuracy trade-off.
- What prevents others from copying your techniques/process? Analogous to the various compression techniques that are available (e.g. zip, rar, 7z etc)
Multiverse Computing’s proprietary CompactifAI technology is a unique approach to AI model compression, based on research into quantum-inspired tensor networks by cofounder and CEO Roman Orus, and the company’s own research team.
What prevents copycat techniques is the technical know-how required to achieve such high rates of compression without sacrificing accuracy.
CompactifAI can reduce model size by up to 95% with only a 2-3% accuracy loss, compared to the industry standard of 20-30% accuracy loss after just 50-60% compression.
CompactifAI - AI Model Compressor - YouTube Watch On
Watch On
Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds. Make sure to click the Follow button!
And of course you can also follow TechRadar on TikTok for news, reviews, unboxings in video form, and get regular updates from us on WhatsApp too.
TOPICS AI Desire AthowSocial Links NavigationManaging Editor, TechRadar Pro
Desire AthowSocial Links NavigationManaging Editor, TechRadar ProDésiré has been musing and writing about technology during a career spanning four decades. He dabbled in website builders and web hosting when DHTML and frames were in vogue and started narrating about the impact of technology on society just before the start of the Y2K hysteria at the turn of the last millennium.
With contributions from View MoreYou must confirm your public display name before commenting
Please logout and then login again, you will then be prompted to enter your display name.
Logout Read more
World's smallest AI supercomputer achieves world record with 120B-parameter LLM support on-device — what I don't understand, though, is how it does OTA hardware upgrades
Sam Altman says ChatGPT water use claims are ‘completely untrue'
Deepseek may have found a way to solve the RAM crisis by eliminating the need for expensive HBM for AI inference and training — yes, the very reason why DRAM prices went up by 5X in 10 weeks
 ‘In AI models, the real bottleneck isn’t computing power — it’s memory’: Phison CEO on 244TB SSDs, PLC NAND, why high-bandwidth flash isn’t a good idea, and why CSP profit goes hand in hand with storage capacity
‘In AI models, the real bottleneck isn’t computing power — it’s memory’: Phison CEO on 244TB SSDs, PLC NAND, why high-bandwidth flash isn’t a good idea, and why CSP profit goes hand in hand with storage capacity
 ChatGPT 5.2 is here and ready to show you professional AI
ChatGPT 5.2 is here and ready to show you professional AI
 “The AI data centers of 2036 won’t be filled with GPUs”: FuriosaAI’s CEO on the future of silicon
Latest in Pro
“The AI data centers of 2036 won’t be filled with GPUs”: FuriosaAI’s CEO on the future of silicon
Latest in Pro
 “AI in networks isn’t CPU vs. GPU”: Intel unveils 18A-based Clearwater Forest Xeon 6+ for edge AI and early 6G infrastructure
“AI in networks isn’t CPU vs. GPU”: Intel unveils 18A-based Clearwater Forest Xeon 6+ for edge AI and early 6G infrastructure
 No, the sub-$500 PC market will not disappear by 2028 - Au contraire, I expect it to thrive. Here's why
No, the sub-$500 PC market will not disappear by 2028 - Au contraire, I expect it to thrive. Here's why
 ‘I can think of a couple Pretti Good reasons!’: Hacktivists may have just cracked open ICE and exposed over 6,000 companies working with the DHS
‘I can think of a couple Pretti Good reasons!’: Hacktivists may have just cracked open ICE and exposed over 6,000 companies working with the DHS
 2025 was the year AI grew up. How will AI evolve in 2026?
2025 was the year AI grew up. How will AI evolve in 2026?
 Seagate reveals Mozaic 4+, its highest-capacity hard drives ever, offering up to 44TB for the next generation of storage
Seagate reveals Mozaic 4+, its highest-capacity hard drives ever, offering up to 44TB for the next generation of storage
 This new phishing campaign uses a fake Google Account security page to steal passcodes and more
Latest in Features
This new phishing campaign uses a fake Google Account security page to steal passcodes and more
Latest in Features
 Forget the Nintendo Switch 2, MWC 2026 is full of brilliant mobile gaming devices, including the Red Magic Astra
Forget the Nintendo Switch 2, MWC 2026 is full of brilliant mobile gaming devices, including the Red Magic Astra
 Marathon is a different kind of extraction shooter, and it won’t be for everyone
Marathon is a different kind of extraction shooter, and it won’t be for everyone
 'She's a 10, but also decaying' — the five zombies from Resident Evil Requiem I wish I could be friends with
“Rewriting the blueprint, not removing bricks”: Multiverse Computing says it can shrink large AI models and cut memory use in half
'She's a 10, but also decaying' — the five zombies from Resident Evil Requiem I wish I could be friends with
“Rewriting the blueprint, not removing bricks”: Multiverse Computing says it can shrink large AI models and cut memory use in half
 Hands on with the Honor Magic V6, the new wafer-thin foldable battery behemoth
Hands on with the Honor Magic V6, the new wafer-thin foldable battery behemoth
 5 things nobody tells you when you move from ChatGPT to Claude
LATEST ARTICLES
5 things nobody tells you when you move from ChatGPT to Claude
LATEST ARTICLES- 1“Rewriting the blueprint, not removing bricks”: Multiverse Computing says it can shrink large AI models and cut memory use in half
- 2Apple’s new Studio Display is missing a key feature that will leave Mac gamers disappointed
- 3Is your TV's picture too dark? Here are the settings you should change to help
- 4Marathon is a different kind of extraction shooter, and it won’t be for everyone
- 5MWC 2026 day 2: the 7 best gadgets we've seen today, from e-paper phones to tiny SSDs