
- Pro
DeepSeek's Engram separates static storage from computation
When you purchase through links on our site, we may earn an affiliate commission. Here’s how it works.
 (Image credit: Adobe Stock)
Share
Share by:
(Image credit: Adobe Stock)
Share
Share by:
- Copy link
- X
- Threads
- DeepSeek’s Engram separates static memory from computation, increasing efficiency in large AI models
- The method reduces high-speed memory needs by enabling DeepSeek models to use lookups
- Engram supports asynchronous prefetching across multiple GPUs with minimal performance overhead
DeepSeek, in collaboration with Peking University, introduced a new training method called Engram, designed to decouple memory storage from computational processes.
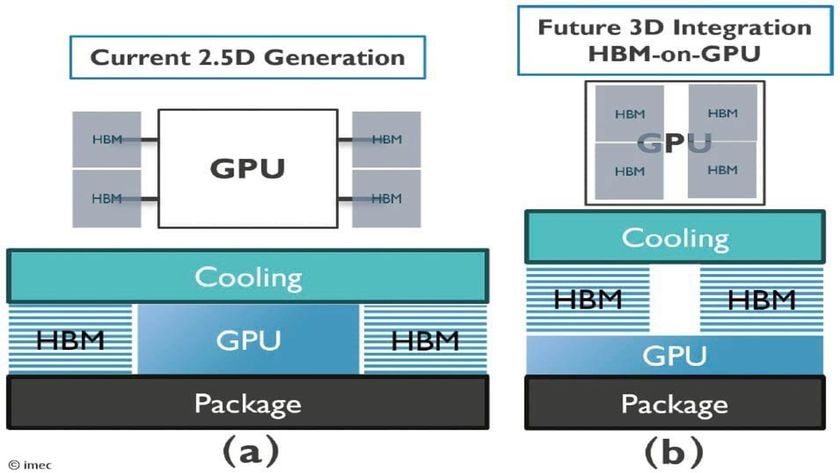
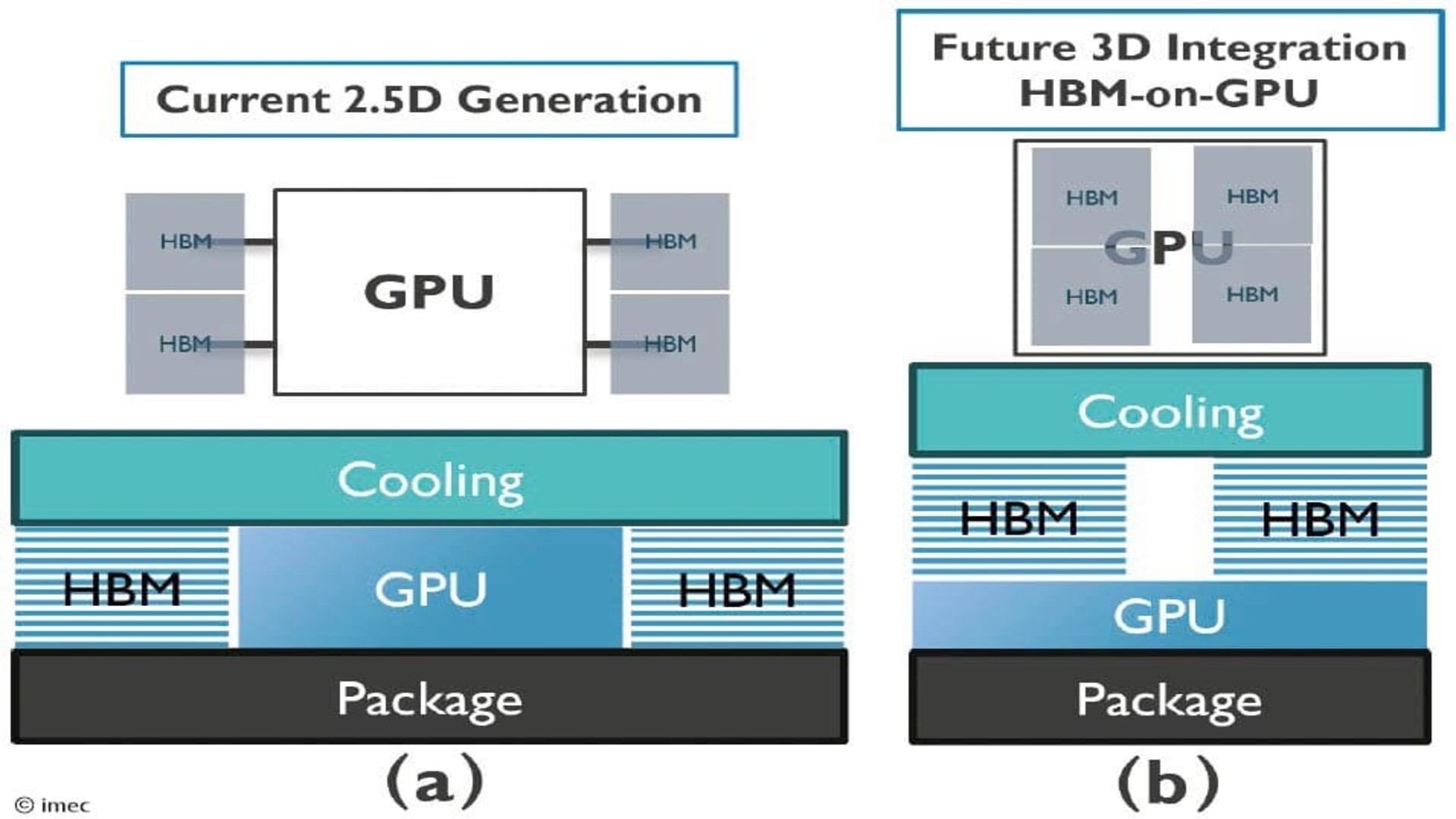
Traditional large language models require high-bandwidth memory for knowledge retrieval and basic computation, creating a bottleneck in both performance and cost.
This HBM bottleneck is widely recognized as a key reason DRAM prices rose by 5X in just 10 weeks, as hardware demand spiked to support large AI models.
You may like-
 ‘In AI models, the real bottleneck isn’t computing power — it’s memory’: Phison CEO on 244TB SSDs, PLC NAND, why high-bandwidth flash isn’t a good idea, and why CSP profit goes hand in hand with storage capacity
‘In AI models, the real bottleneck isn’t computing power — it’s memory’: Phison CEO on 244TB SSDs, PLC NAND, why high-bandwidth flash isn’t a good idea, and why CSP profit goes hand in hand with storage capacity
-
 The associative processing unit wants to displace Nvidia's GPU as the go-to AI powerhouse by putting compute in the memory itself
The associative processing unit wants to displace Nvidia's GPU as the go-to AI powerhouse by putting compute in the memory itself
-
 HBM-on-GPU set to power the next revolution in AI accelerators - and just to confirm, there's no way this will come to your video card anytime soon
HBM-on-GPU set to power the next revolution in AI accelerators - and just to confirm, there's no way this will come to your video card anytime soon
Validation and technical approach
The researchers said existing models waste sequential depth on trivial operations, which could otherwise support higher-level reasoning.
Engram allows models to efficiently “look up” essential information without overloading GPU memory, freeing capacity for more complex reasoning tasks.
The system was tested on a 27-billion-parameter model and showed measurable improvements across standard industry benchmarks.
By performing knowledge retrieval through hashed N-grams, Engram provides static memory access independent of the current context.
Are you a pro? Subscribe to our newsletterContact me with news and offers from other Future brandsReceive email from us on behalf of our trusted partners or sponsorsBy submitting your information you agree to the Terms & Conditions and Privacy Policy and are aged 16 or over.The retrieved information is then adjusted using a context-aware gating mechanism to align with the model’s hidden state.
This design allows models to handle long context inputs more efficiently and supports system-level prefetching with minimal performance overhead.
The Engram method complements other hardware-efficient approaches, including solutions such as Phison’s AI inference accelerators.
You may like-
‘In AI models, the real bottleneck isn’t computing power — it’s memory’: Phison CEO on 244TB SSDs, PLC NAND, why high-bandwidth flash isn’t a good idea, and why CSP profit goes hand in hand with storage capacity
-
The associative processing unit wants to displace Nvidia's GPU as the go-to AI powerhouse by putting compute in the memory itself
-
HBM-on-GPU set to power the next revolution in AI accelerators - and just to confirm, there's no way this will come to your video card anytime soon
Engram minimizes the amount of high-speed memory required by using lookups for static information, making memory usage more efficient.
Phison offers a cost-effective way to expand total memory using SSDs, supporting large AI models such as Engram or Mixture-of-Experts systems.
Combined, these approaches allow AI systems to optimize fast-memory usage while affordably increasing overall memory capacity.
It also works alongside emerging CXL (Compute Express Link) standards, which aim to overcome GPU memory bottlenecks in large-scale AI workloads.
The method separates static pattern storage from dynamic computation, enhancing the Transformer backbone without increasing FLOPs or parameter counts.
DeepSeek formalized a U-shaped expansion rule to optimize the allocation of parameters between the MoE conditional computation module and the Engram memory module.
Tests show that reallocating around 20–25% of the sparse parameter budget to Engram yields better performance than pure MoE models, maintaining stable gains across different scales.
Memory slot expansion provides predictable improvements without additional computational cost.
This confirms the scalability of conditional memory as an independent axis for sparse models.
Engram’s deterministic retrieval mechanism allows memory capacity to scale linearly across multiple GPUs while supporting asynchronous prefetching during inference.
It offloads static knowledge reconstruction from lower layers, freeing attention mechanisms to focus on global context.
Hierarchical caching of frequently used embeddings enhances efficiency, and the module works with existing GPU and system memory architectures, potentially avoiding costly HBM upgrades.
This technique may relieve pressure on expensive memory hardware, particularly in regions such as China, where HBM access lags behind competitors such as Samsung, SK Hynix, and Micron.
Early validation of Engram suggests models can expand parameter scale and reasoning capacity while managing memory demands more efficiently.
This approach may help ease memory constraints across AI infrastructure, potentially reducing sharp DDR5 DRAM price swings.
Via SCMP
Follow TechRadar on Google News and add us as a preferred source to get our expert news, reviews, and opinion in your feeds. Make sure to click the Follow button!
And of course you can also follow TechRadar on TikTok for news, reviews, unboxings in video form, and get regular updates from us on WhatsApp too.
 Efosa UdinmwenFreelance Journalist
Efosa UdinmwenFreelance JournalistEfosa has been writing about technology for over 7 years, initially driven by curiosity but now fueled by a strong passion for the field. He holds both a Master's and a PhD in sciences, which provided him with a solid foundation in analytical thinking.
Show More CommentsYou must confirm your public display name before commenting
Please logout and then login again, you will then be prompted to enter your display name.
Logout Read more ‘In AI models, the real bottleneck isn’t computing power — it’s memory’: Phison CEO on 244TB SSDs, PLC NAND, why high-bandwidth flash isn’t a good idea, and why CSP profit goes hand in hand with storage capacity
‘In AI models, the real bottleneck isn’t computing power — it’s memory’: Phison CEO on 244TB SSDs, PLC NAND, why high-bandwidth flash isn’t a good idea, and why CSP profit goes hand in hand with storage capacity
 The associative processing unit wants to displace Nvidia's GPU as the go-to AI powerhouse by putting compute in the memory itself
The associative processing unit wants to displace Nvidia's GPU as the go-to AI powerhouse by putting compute in the memory itself
 HBM-on-GPU set to power the next revolution in AI accelerators - and just to confirm, there's no way this will come to your video card anytime soon
HBM-on-GPU set to power the next revolution in AI accelerators - and just to confirm, there's no way this will come to your video card anytime soon
 New 'serial' tech will significantly reduce the cost of memory — HBM memory, that is, the sort of RAM only AI hyperscalers can use, but hey, at least they won't go after consumer RAM, or would they?
New 'serial' tech will significantly reduce the cost of memory — HBM memory, that is, the sort of RAM only AI hyperscalers can use, but hey, at least they won't go after consumer RAM, or would they?
 Why is RAM so expensive right now? It's way more complicated than you think
Why is RAM so expensive right now? It's way more complicated than you think
 This tiny chip could single-handedly solve the RAM shortage by allowing hyperscalers to reuse old DDR4 memory via CXL — and it comes with an extraordinary feature
Latest in Pro
This tiny chip could single-handedly solve the RAM shortage by allowing hyperscalers to reuse old DDR4 memory via CXL — and it comes with an extraordinary feature
Latest in Pro
 Best n8n hosting
Best n8n hosting
 Forget lasers and missiles, China wants to kill drones using a common tech households use everyday in kitchens all around the world — invisible microwave weapons can fry electronics but still require line-of-sight and proximity
Forget lasers and missiles, China wants to kill drones using a common tech households use everyday in kitchens all around the world — invisible microwave weapons can fry electronics but still require line-of-sight and proximity
 'It’s like wrapping the wind from all sides': Drone-like airship with 24 blades is world's first megawatt-class tethered wind turbine — S2000 rises to 2Km and can generate a whopping 3MW
'It’s like wrapping the wind from all sides': Drone-like airship with 24 blades is world's first megawatt-class tethered wind turbine — S2000 rises to 2Km and can generate a whopping 3MW
 A 3D printed drone is probably the world's fastest DIY plane ever, quicker than even the legendary P38 Lightning — but at 408mph, it has some way to go to catch up with the 575mph TU-95
A 3D printed drone is probably the world's fastest DIY plane ever, quicker than even the legendary P38 Lightning — but at 408mph, it has some way to go to catch up with the 575mph TU-95
 7 high-converting print-on-demand products to add to your website
7 high-converting print-on-demand products to add to your website
 5 income streams you can add to your website right now
Latest in News
5 income streams you can add to your website right now
Latest in News
 NYT Connections hints and answers for Sunday, January 18 (game #952)
NYT Connections hints and answers for Sunday, January 18 (game #952)
 NYT Strands hints and answers for Sunday, January 18 (game #686)
NYT Strands hints and answers for Sunday, January 18 (game #686)
 Quordle hints and answers for Sunday, January 18 (game #1455)
Quordle hints and answers for Sunday, January 18 (game #1455)
 Apple's OLED touchscreen MacBook Pro upgrade could arrive early
Apple's OLED touchscreen MacBook Pro upgrade could arrive early
 Samsung Galaxy S26 leak shows no sign of the Pro or Edge models
Samsung Galaxy S26 leak shows no sign of the Pro or Edge models
 ChatGPT ads are coming — OpenAI confirms and explains how they'll work
LATEST ARTICLES
ChatGPT ads are coming — OpenAI confirms and explains how they'll work
LATEST ARTICLES- 1Deepseek may have found a way to solve the RAM crisis by eliminating the need for expensive HBM for AI inference and training — yes, the very reason why DRAM prices went up by 5X in 10 weeks
- 2Quordle hints and answers for Sunday, January 18 (game #1455)
- 3NYT Strands hints and answers for Sunday, January 18 (game #686)
- 4NYT Connections hints and answers for Sunday, January 18 (game #952)
- 5What exactly is a canister vacuum, and what are they good for?